Using a Web Scraper to add GitHub Stars to my Site
Table of Contents
Whenever I come across something that is either useful, quirky, and just straight up cool, on GitHub, I immediately star it so that I don’t lose it. One feature that I wanted my site to have, even before I built the damn thing, was a way for me to relay my list of starred repos for all to see!
That’s why I just spent the better part of about 4 hours automating the process! :D
Skip to the tl;dr
✨ Reach for the Stars#
My immediate question when it came to fetching the star data was “does GitHub provide an endpoint in their API to access stars?”, and of course the answer was no…
Ok, not to worry, I’ll just scrape the data, I guess? … I then wrote a small web scraper in Python, using the BeautifulSoup web scraper package, that is capable of making a request to https://github.com/[user]?tab=stars, extracting all of the various elements for each star, locating the pagination links, and recursively scraping stars until no pagination link is found.
./scripts/star_scraper.py (get it, like sky scraper but even h i g h e r)
import argparse
from datetime import datetime
from urllib.parse import urlparse, parse_qs
from bs4 import BeautifulSoup
import json
import requests
# fetch_github_stars makes a request to github.com/{username}?tab=stars and scrapes the contents of the
# turbo-frame with id "user-starred-repos" and extracts the details of each starred repo, along with the
# pagination url of the next page of results (if there is one)
def fetch_github_stars(username: str, after: str) -> list[str]:
stars = []
url = f"https://github.com/{username}?tab=stars&after={after}"
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# extract all the starred repos
repos = soup.find(id="user-starred-repos")
entries = repos.find_all("div", {"class": "d-block"})
for entry in entries:
repo_link = "https://github.com" + entry.find("a")['href']
repo_name = entry.find("a").text.strip()
repo_description = entry.find("p", {"itemprop": "description"})
if repo_description:
repo_description = repo_description.text.strip()
else:
repo_description = ""
star_count = entry.find("a", href=lambda href: href and "stargazers" in href).text.strip()
language = entry.find("span", {"itemprop": "programmingLanguage"})
language_color = ""
if language:
language = language.text.strip()
language_color = entry.find("span", {"class": "repo-language-color"})['style'].split(":")[1].strip()
else:
language = ""
fork_count = entry.find("a", href=lambda href: href and "forks" in href)
if fork_count:
fork_count = fork_count.text.strip()
else:
fork_count = ""
updated = entry.find("relative-time")['datetime']
stars.append({
"link": repo_link,
"name": repo_name,
"description": repo_description,
"stars": star_count,
"language": language,
"language_color": language_color,
"forks": fork_count,
"updated": updated
})
# extract pagination link
pagination_link = soup.find('a', {'rel': 'nofollow', 'href': lambda x: 'after' in x})
if pagination_link:
pagination_link = pagination_link['href']
parsed_url = urlparse(pagination_link)
query_params = parse_qs(parsed_url.query)
pagination_link = query_params.get('after', [None])[0]
return stars, pagination_link
# fetch_github_stars_recursive recursively fetches all the stars for a given user
def fetch_github_stars_recursive(username: str, after: str) -> list[str]:
stars, pagination_link = fetch_github_stars(username, after)
if pagination_link:
stars += fetch_github_stars_recursive(username, pagination_link)
return stars
def main():
parser = argparse.ArgumentParser(description='Fetch GitHub stars for a user')
parser.add_argument('-u', '--username', required=True, help='GitHub username')
args = parser.parse_args()
stars = fetch_github_stars_recursive(args.username, '')
data = {
"username": args.username,
"last_updated": datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ"),
"stars": stars
}
data = json.dumps(data, indent=4)
print(data)
if __name__ == "__main__":
main()
./scripts/requirements.txt
beautifulsoup4==4.12.2
requests==2.31.0
With Python installed, simply run the following after replacing the username flag with the desired GitHub username:
pip install -r ./scripts/requirements.txt
python ./scripts/star_scraper.py -u taylow > ./assets/data/stars.json
You should be left with a file named stars.json that looks like like this:
{
"username": "taylow",
"last_updated": "2023-12-18T02:15:51Z",
"stars": [
{
"link": "https://github.com/golang/go",
"name": "golang / go",
"description": "The Go programming language",
"stars": "116,440",
"language": "Go",
"language_color": "#00ADD8",
"forks": "17,457",
"updated": "2023-12-17T12:56:45Z"
}
]
}
🤖 Automate the Scrape#
Having the scraper was all well and good, but I really don’t want to have to remember to run this thing whenever I star a new repo, so I did what I do with all tedious tasks and automate it!
I created a GitHub Actions workflow that runs on a cron schedule every night at 12am, pulls the repo, sets up python, runs the star scraper, and commits and pushes the updated stars.json file!
.github/workflows/reach-for-the-stars.yml
name: Reach for the stars
on:
workflow_dispatch:
schedule:
- cron: '0 0 * * *' # every day at midnight
jobs:
fetch-stars:
runs-on: ubuntu-latest
steps:
- name: checkout code
uses: actions/checkout@v4
- name: setup python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: install python packages
run: |
python -m pip install --upgrade pip
pip install -r ./scripts/requirements.txt
- name: scrape stars
run: |
python ./scripts/star_scraper.py -u taylow > ./assets/data/stars.json
- name: commit files
run: |
git config --local user.email "action@github.com"
git config --local user.name "GitHub Action"
git add -A
git diff-index --quiet HEAD || (git commit -a -m "chore: update stars" --allow-empty)
- name: push changes
uses: ad-m/github-push-action@v0.8.0
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
branch: main
This must be followed with whatever code you use to deploy your site!
💅 Make it Pretty#
This step is where it gets a bit subjective, as not everyone will be using the same Blowfish Hugo theme as I am, and probably share a different definition of the word pretty!
That said, I just wanted it to look cool, and sorta like how it looks on GitHub, so I spent way longer than I did on everything up to this point and built a Hugo shortcode that creates a timeline with all of the details of each star.
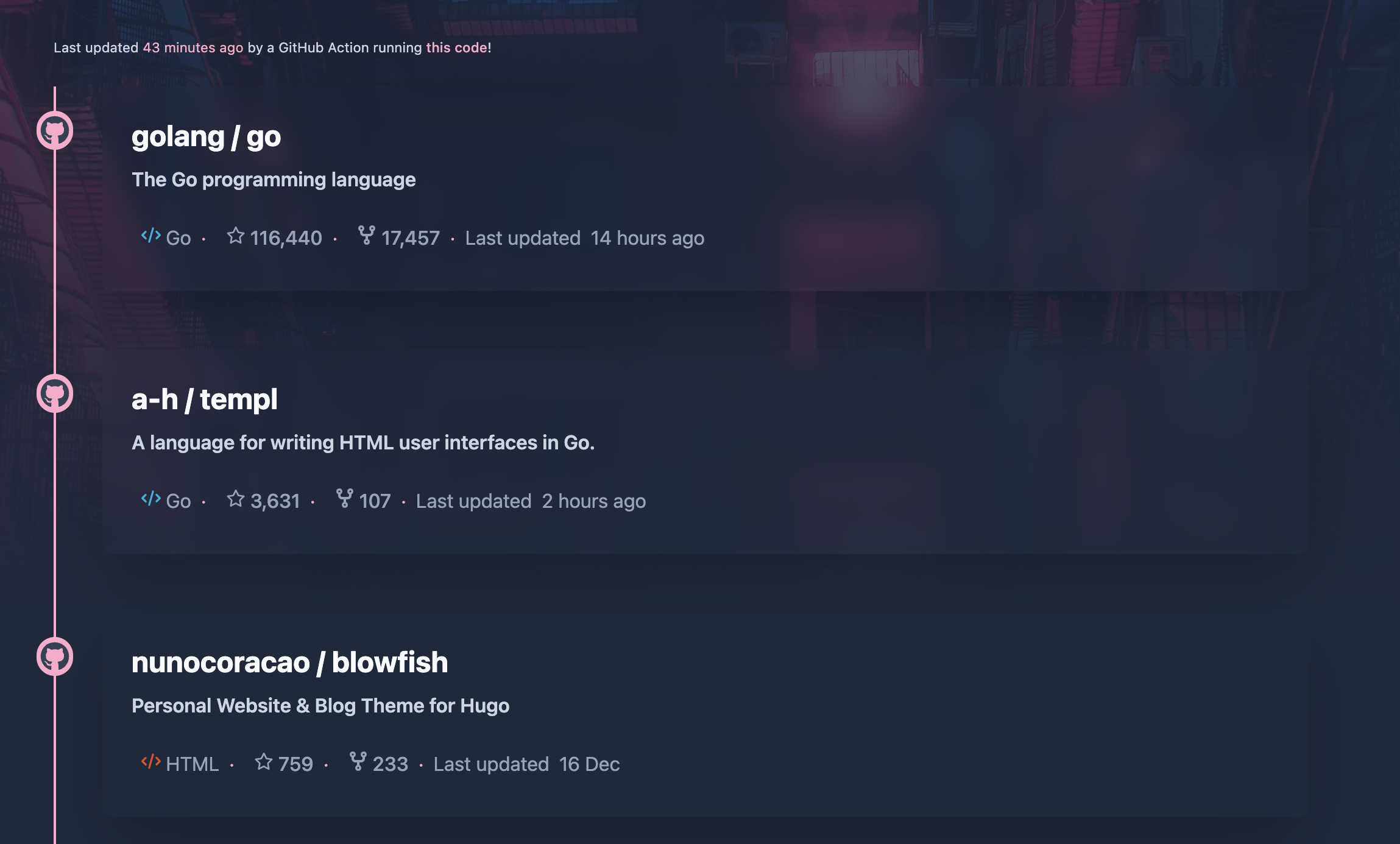
./layouts/shortcodes/githubStars.html
<script>
document.addEventListener('DOMContentLoaded', (event) => {
document.querySelectorAll('.timeago').forEach(function(node) {
node.textContent = timeAgo(new Date(node.getAttribute('datetime')));
});
});
function timeAgo(date) {
const now = new Date();
const secondsPast = (now.getTime() - date.getTime()) / 1000;
if(secondsPast < 60){
return parseInt(secondsPast) + (secondsPast > 1 ? ' seconds ago' : ' second ago');
}
if(secondsPast < 3600){
return parseInt(secondsPast/60) + (parseInt(secondsPast/60) > 1 ? ' minutes ago' : ' minute ago');
}
if(secondsPast <= 86400){
return parseInt(secondsPast/3600) + (parseInt(secondsPast/3600) > 1 ? ' hours ago' : ' hour ago');
}
if(secondsPast > 86400){
day = date.getDate();
month = date.toDateString().match(/ [a-zA-Z]*/)[0].replace(" ","");
year = date.getFullYear() == now.getFullYear() ? "" : " " + date.getFullYear();
return day + " " + month + year;
}
}
</script>
{{ $stars := dict }}
{{ $path := "data/stars.json" }}
{{ with resources.Get $path }}
{{ with . | transform.Unmarshal }}
{{ $stars = . }}
{{ end }}
{{ else }}
{{ errorf "Unable to get global resource %q" $path }}
{{ end }}
<span class="smallish-text">Last updated <span class="text-primary-500"><time class="timeago" datetime="{{ $stars.last_updated }}"></time></span> by a GitHub Action running <a href="https://gist.github.com/taylow/09ad65b795c18fc273d64d850ba7c406">this code</a>!</span>
{{ if $stars.stars }}
<ol class="border-l-2 list-none border-primary-500 dark:border-primary-300">
{{ range $stars.stars }}
<li class="list-none">
<div class="flex flex-start">
<div class="bg-primary-500 dark:bg-primary-300 text-neutral-50 dark:text-neutral-700 min-w-[30px] h-8 text-2xl flex items-center justify-center rounded-full -ml-12 mt-5">
{{ partial "icon" "github" }}
</div>
<div class="block p-6 rounded-lg shadow-2xl min-w-full ml-6 mb-10 backdrop-blur">
<div class="flex">
<a href="{{ .link }}">
<h2 class="mt-0 mb-2 hover:text-primary-400">
{{ .name }}
</h2>
</a>
</div>
{{ if .description }}
<h4 class="mt-0 mb-2 text-neutral-400 dark:text-neutral-300">
{{ .description }}
</h4>
{{ end }}
<div class="mt-6 mb-2 text-base text-neutral-500 dark:text-neutral-400 print:hidden">
<div style="cursor: default;" class="flex flex-row flex-wrap items-center">
<span>
<span class="inline-block align-text-middle pr-2" style="color: {{ .language_color }}">{{ partial "icon.html" "code" }}</span>
<span>{{ .language }}</span>
</span>
<span class="px-2 text-primary-500">·</span>
<a href="{{ .link }}/stargazers" class="flex flex-row flex-wrap items-center text-neutral-500 dark:text-neutral-400">
<span>
<span class="inline-block align-text-middle pr-2">{{ partial "icon.html" "star" }}</span>
<span>{{ .stars }}</span>
</span>
</a>
<span class="px-2 text-primary-500">·</span>
<a href="{{ .link }}/forks" class="flex flex-row flex-wrap items-center text-neutral-500 dark:text-neutral-400">
<span>
<span class="inline-block align-text-middle pr-2">{{ partial "icon.html" "fork" }}</span>
<span>{{ .forks }}</span>
</span>
</a>
<span class="px-2 text-primary-500">·</span>
<span class="pr-2">Last updated</span> <time class="timeago" datetime="{{ .updated }}"></time>
</div>
</div>
</div>
</div>
</li>
{{ end }}
</ol>
{{ else }}
<p class="mx-10 text-neutral-500 dark:text-neutral-400 flex justify-center">No starred repositories found!</p>
{{ end }}
You’ll have to style it yourself, as most of the stylings come from Blowfish, other than a few bits like smallish-text, which is just smallish text…
🧐 Findings#
This was a neat little project, as it let me touch on various skills to make something silly and unnecessarily extra. That said, I did try a few things that aren’t highlighted in this blog.
I originally intended to write the scraper as a Firebase Cloud Function, but realised I had to move onto the Blaze package to use cloud functions… Maybe this can be a future upgrade for when I do move onto that plan. This would let me simply update the data and not have to build and deploy a whole website every night - though it only takes a minute 🤷♀️
I tried chaining workflows together by using the
workflow_calltrigger; having the star scraping workflow use the existing deployment workflow. I opted against it in the end, as the existing workflow already builds and deploys on push. It was cool chaining separate workflow files together though, and I absolutely will be using that more in the future!Web scraping is always fun. There’s just something about writing a little blob of code that takes a human-readable site and strips it back down into raw data, especially when it comes to sites that don’t provide an API! (although, there has been a lot of discussion about adding this API endpoint, so who knows, maybe I’ll change it in the future!)
Star lists are a thing… I only realised after I was done that I can actually organise my stars into lists, so I absolutely will be doing that, and will update my site (Eventually™) to have groups and filters!
I really enjoy Hugo, it just makes sense!
😴 tl;dr#
- I wanted to relay my GitHub Stars to my site
- GitHub doesn’t currently offer a way to fetch that data via their API
- I wrote a recursive web crawler in Python that fetches all stars from the stars tab of a given user
- I made a scheduled workflow to automatically fetch this data daily at 12am
- I added a Hugo shortcode to display the data in a timeline format similar to the GitHub style
🚧 Deprecation & Maintenance#
Since writing this, a few things have changed with Hugo. The main difference is the deprecation of the getJSON function. This has been replaced with resources.Get piped through the transform.Unmarshal function.
Replace
{{ $stars := getJSON "assets/data/stars.json" }}
With
{{ $stars := dict }}
{{ $path := "data/stars.json" }}
{{ with resources.Get $path }}
{{ with . | transform.Unmarshal }}
{{ $stars = . }}
{{ end }}
{{ else }}
{{ errorf "Unable to get global resource %q" $path }}
{{ end }}
Don’t forget to bump your hugo version in the deploy portion of your GitHub Action!